I’ve been trying to figure out the cause of a SQL deadlock problem, and it dawned on me that preventing deadlocks shouldn’t be that hard. You just have to save data in the same order every time, and the easiest way to do that is to have a repository with one save method. I’ll show you what a deadlock is, and how to prevent them.
Month: April 2024
What’s the difference between Span of T and Memory of T?

What’s the difference between Span of T and Memory of T? My goal is not to tell you how awesome they are, but to get you over the hump of understanding how they work. I cover what they do and why, along with some description of their internals. Finally, I discuss what the owner consumer model is, and why it’s relevant to Memory of T.
Loading Millions Of Rows Of Test Data In Seconds

Most tools that generate test data do so iteratively. But SQL loves set based operations. With a little T-SQL know how, you can create millions of rows of test data in seconds. You can even leverage public data sources to create more realistic data that conforms to your applications business rules. No third party tools, just a handful of queries. I’m keeping it simple.
Generating Geographic Test Data With T-SQL and ChatGPT

When you need lots of test data (100K+) for addresses that represent real places you could leverage ChatGPT and some T-SQL wizardry.
To do this I asked ChatGPT to give me a list of all the US state capitols and include their longitude and latitude, then turn the data into a TSQL insert statement.
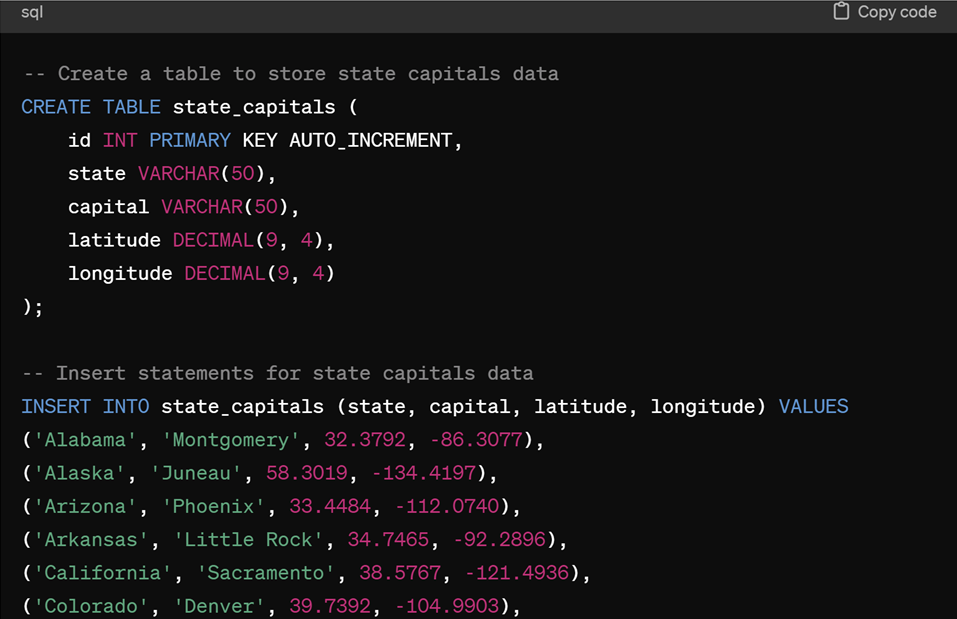
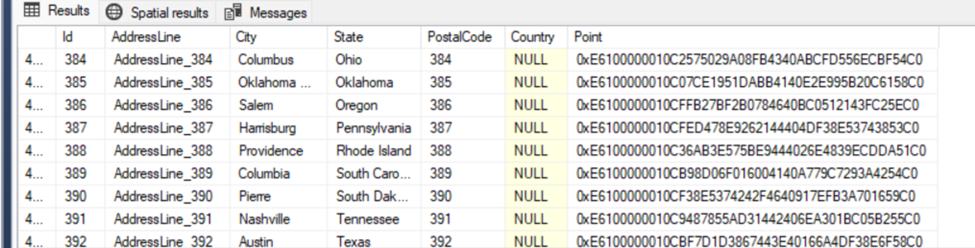
That gives me the longitude and latitude of a point in each state. I created an Address table that will store a list of addresses.

I want to create 100000 rows in the address table. SQL is really good at manipulating sets of data, so I want to insert rows into the table with a single insert statement, to make the process faster. To do that I’m going to create a table variable and populate it with a list of integers. Lots of integers.
Once the table is created, I can insert a single row to seed the table, with the number 1. A while loop can be used to double the number of inserts over each iteration by selecting all the rows in the table and multiplying the integer by 2.
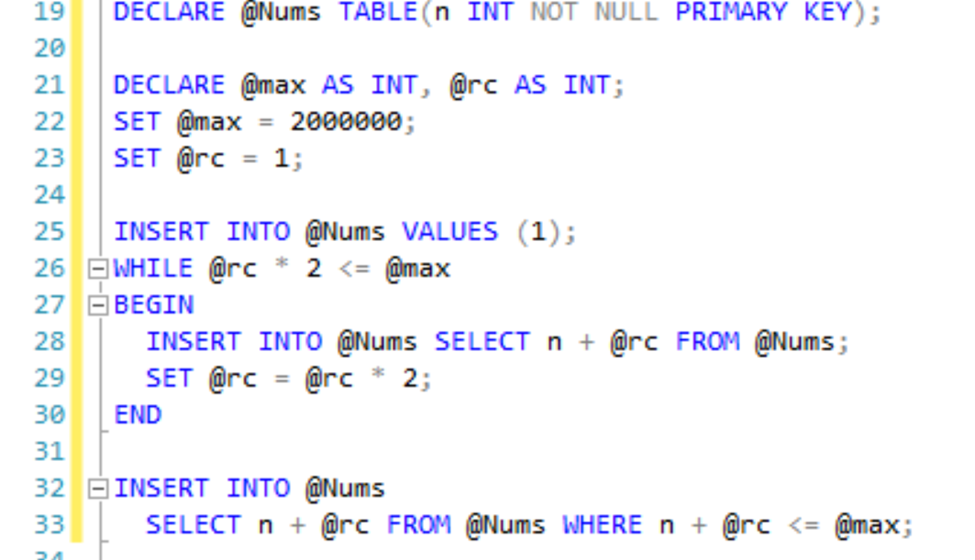
Now that we have a table of integers from 1 to 2,000,000, I can use the table to create new data.
I’ll select all the rows from the @Nums table where the number is less than or equal to the number of addresses I want to create. In this case 100,000. I also want to join with the table of state capitals, so I can use the city, state, longitude and latitude fields to populate the data. I can use the modulus operator to match with one of the 50 rows in the state capitols table.

To convert the longitude and latitude to a geography column type, I can use the STGeomFromText function. If you needed locations with more variance, you could add a small random value to the longitude and latitude of each row as it’s inserted into the address table. The script took about 15 seconds to populate the table, but most of the time was in calculating the geography value, so using the table of numbers to generate data is very fast.