
I’ve been trying to figure out the cause of a SQL deadlock problem, and it dawned on me that preventing deadlocks shouldn’t be that hard. You just have to save data in the same order every time, and the easiest way to do that is to have a repository with one save method. I’ll show you what a deadlock is, and how to prevent them.
Category: MS SQL
Loading Millions Of Rows Of Test Data In Seconds

Most tools that generate test data do so iteratively. But SQL loves set based operations. With a little T-SQL know how, you can create millions of rows of test data in seconds. You can even leverage public data sources to create more realistic data that conforms to your applications business rules. No third party tools, just a handful of queries. I’m keeping it simple.
Supercharged Dapper Repositories
Part #1: Separate Filters From Queries
Dapper has been a really popular data access library for over a decade, but when it comes to use it with domain entities, there are a few things that can create friction. In this series, I want to show you how to supercharge your Dapper repositories to be faster and more maintainable.
Sample Code: https://github.com/JZuerlein/DapperPopulateAggregate
Paging Data With SQL Server and C#
Learn about several strategies to improve the performance of paging data with .Net and SQL Server, as well as different ways to measure the impact of your software.
NPI data is available at CMS.gov https://download.cms.gov/nppes/NPI_Files.html
SqlConnection Statistics For SQL Server https://learn.microsoft.com/en-us/dotnet/framework/data/adonet/sql/provider-statistics-for-sql-server
Jeff Zuerlein https://www.linkedin.com/in/jeff-zuerlein-2aa67b7/
Entity Framework Core – Creating Schemas With the FluentAPI

What’s the difference between storing data in Excel and SQL Server? Schema.
A good schema can help maintain the integrity of your data, and improve the performance of your application. Entity Framework makes it so easy to create a new database, that it’s easy to forget what’s going on under the hood. I’ll present some techniques to make EF create databases with indexes, foreign keys, constraints, and inheritance using the Fluent API.
Entity Framework has three methods to create a database schema. The default method is “convention”. It uses built in rules based on the name of properties, and entity composition to create the schema. It’s the method most people use to get started, but you don’t have any control over them. Another way to configure the schema is to use annotations on the entity model to dictate how the schema is created. The last and most powerful, is to use the Fluent API. Configuration options you make using the Fluent API override annotations and conventions. Below is a common data model that I’ll use in my examples.
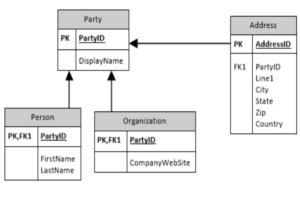
Identities and Constraints
EF will make the best choice it can when configuring the schema. For example, if the primary key is an integer, it will make the column an identity column by default. For every row that is added, the PK is set to the next highest integer in the column. If you wanted to be explicit about this option, you could do that by overriding the OnModelCreating method of the DbContext object.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | public class CRMContext : DbContext{ public DbSet<Address> Addresses {get; set;} public DbSet<Party> Party {get; set;} public DbSet<Person> People {get; set;} public DbSet<Organization> Organizations {get; set;} protected override void OnModelCreating(ModelBuilder modelBuilder) { modelBuilder.Entity<Party>() .Property(p => p.PartyID .UseSqlServerIdentityColumn(); }} |
Another convention that EF uses, is to create NVARCHAR(MAX) columns to store string data. It’s a safe guess because it’s flexible in the absence of knowledge about what kind of data will be stored. If you know that a column will be storing the names of people, you could specify the maximum length the column will store, and improve performance.
1 2 3 4 5 | modelBuilder.Entity<Party>().Property(p => p.DisplayName).HasMaxLength(128); |
Foreign Keys
In this example, a person or organization inherits from a party. Each has a collection of addresses that can be associated with them. This relationship is defined by creating a foreign key property on the database schema. Using the Fluent API, we begin by declaring the navigation properties of the relationship. This can be defined as “HasOne” or “HasMany”, depending on the carnality of the relationship. The inverse navigation can be chained to the definition by using “WithOne” or “WithMany”.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | protected override void OnModelCreating(ModelBuilder modelBuilder){ modelBuilder.Entity<Party>() .HasMany(p => p.Addresses) .WithOne(p => p.Party) .HasForeignKey(p => p.PartyID) .IsRequired() .OnDelete(DeleteBehavior.Cascade);} |
After establishing the relationship and its carnality, we need to tell Entity Framework what the foreign key field is. This is done using HasForeignKey(). It doesn’t make sense to have an address that is not attached to a person or organization, so the foreign key should be required. This is done with the IsRequired() method. Because an address is tied to a party, when a party is deleted, we want the related addresses to be deleted as well. Cascading deletes in SQL Server can handle this problem for us, so we’ll apply that behavior with the OnDelete method.
Indexes
The next step is to create some indexes on the entities to improve performance. The HasIndex method is used to create an index based on one or more columns. By default the indexes do not require that each “row” be unique. That can be configured by using IsUnique.
1 2 3 4 5 6 7 8 9 10 11 | protected override void OnModelCreating(ModelBuilder modelBuilder){modelBuilder.Entity<Party>().HasIndex(p => new { p.PartyID, p.DisplayName }).IsUnique();} |
Inheritance
Inheritance in a database can take on two distince flavors. The table-per-hierarchy (TPH) pattern uses a single table to store all the data for all the types in the hierarchy. The table-per-type (TPT) pattern creates a table for each type in the hierarchy. Entity Framework currently only supports TPH. Because data for multiple types will be stored in the same table, an additional piece of information is needed to identify a row’s type. In EF, this column is called the discriminator. It can be added to the schema with the HasDiscriminator method. The values that can be placed in column are defined with the HasValue method.
1 2 3 4 5 6 7 8 9 10 11 12 13 | protected override void OnModelCreating(ModelBuilder modelBuilder){modelBuilder.Entity<Party>().HasDiscriminator<string>("PartyType").HasValue<Person>("Person").HasValue<Organization>("Organization");} |

Because EF is using TPH, the Person DbSet and the Organization DbSet are merged into a Party table. This does limit our ability to use SQL constraints to enforce data integerity. For example, if we need to record the schools that a person has attended, there will be no foreign key constraint that can limit this to people. To prevent an organization from attending a school, we would need to create a insert and update trigger on the School table. TPT modeling would let us avoid having to use a trigger. At this point EF doesn’t support TPT modeling, but it is on Microsoft’s roadmap. Another thing to take note of is that the extensions needed to set the discriminator are in the Microsoft.EntityFrameworkCore.Relational package in NuGet.
What do you do when you run DBCC CHECKDB and you find corruption?
Data in SQL databases will become corrupted, eventually. Thankfully there are several mechanisms in SQL Server to protect against it, and warn you that there is a problem. One of the most difficult things to learn about, to train for, is database corruption. Most of us don’t have a set of corrupted databases that we can practice repairing. Learning how to repair them in the heat of the moment is stressful, and often poor decisions can be made. With that in mind, I’ve created some tutorials along with corrupted databases for you to practice on. Download the Northwnd.mdf and Northwnd.ldf, attach them to a SQL Server, and run DBCC CHECKDB on the database. You will see an error message that looks like this.
DBCC results for ‘NORTHWND’.
Msg 8939, Level 16, State 98, Line 1
Table error: Object ID 0, index ID -1, partition ID 0, alloc unit ID 1056009275703296 (type Unknown), page (32993:-2015636120). Test (IS_OFF (BUF_IOERR, pBUF->bstat)) failed. Values are 133129 and -1.
Msg 8928, Level 16, State 1, Line 1
Object ID 2137058649, index ID 3, partition ID 984479205752832, alloc unit ID 984479205752832 (type In-row data): Page (1:295) could not be processed. See other errors for details.
Msg 8980, Level 16, State 1, Line 1
Table error: Object ID 2137058649, index ID 3, partition ID 984479205752832, alloc unit ID 984479205752832 (type In-row data). Index node page (0:0), slot 0 refers to child page (1:295) and previous child (0:0), but they were not encountered.
CHECKDB found 0 allocation errors and 2 consistency errors in table ‘Suppliers’ (object ID 2137058649).
CHECKDB found 0 allocation errors and 3 consistency errors in database ‘NORTHWND’.
repair_allow_data_loss is the minimum repair level for the errors found by DBCC CHECKDB (NORTHWND).
At first glance, this looks like a horrible error message. You might be tempted to try recovering the database from a backup, or running DBCC CHECKDB(NORTHWND, REPAIR_REBUILD). But it wouldn’t be necessary in this case. The key to understanding how to solve database corruption problems is to understand what corruption is, and what the error messages are telling you.
What is corruption?
Database corruption is simply a sequence of ones and zeros that got written to a datafile where they should not have been. Sometimes this happens when a hard disk fails to physically perform as it should, a device driver encounters a bug, or some part of the IO subsystem faults. It doesn’t happen often, but when it does, the result can be a huge headache.
The Error Messages:
Let’s look at each of the error messages, and figure out what they mean.
Msg 8939 & 8928 – The job of physically reading the data, is done by the buffer pool. When a page of data is read by the buffer pool, the page’s checksum is checked. If it doesn’t match the computed value of the data, an error is thrown. CHCEKDB is telling us there is corruption, and look at the other error messages to see how to deal with it.
Msg 8980 – This message is telling us that there is an error in object ID 2137058649. I can take a look at sys.indexes to see what that object is.
SELECT object_id, name, index_id, type, type_description FROM sys.indexes WHERE object_id = 2137958649
object_id name index_id type
———– —————————– ———– —-
2137058649 PK_Suppliers 1 1
2137058649 CompanyName 2 2
2137058649 PostalCode 3 2
(3 row(s) affected)
So now we know that the problem lies in the PostalCode index for the Suppliers table. Lets run a query to verify this.
SELECT PostalCode FROM Suppliers
Msg 824, Level 24, State 2, Line 19
SQL Server detected a logical consistency-based I/O error: torn page (expected signature: 0x00000000; actual signature: 0x55555554). It occurred during a read of page (1:295) in database ID 5 at offset 0x0000000024e000 in file ‘C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\NORTHWND.MDF’. Additional messages in the SQL Server error log or system event log may provide more detail. This is a severe error condition that threatens database integrity and must be corrected immediately. Complete a full database consistency check (DBCC CHECKDB). This error can be caused by many factors; for more information, see SQL Server Books Online.
Note that the torn page error message refers to page (1:295). This matches the error we saw in DBCC CHECKDB. Lets see what happens if we try to query the Suppliers table without using the PostalCode index.
SELECT * FROM Suppliers
No error messages are returned. Indexes are really just metadata, so rather than taking a drastic step like recovering from backup, we can just recreate the index.
DROP INDEX [PostalCode] ON [dbo].[Suppliers]
GO
CREATE NONCLUSTERED INDEX [PostalCode] ON [dbo].[Suppliers]
(
[PostalCode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
After it completes, we can try querying the Suppliers table using the index.
SELECT PostalCode FROM Suppliers
You should now see a list of the postal codes from the table. Now lets run DBCC CHECKDB to see how it looks.
CHECKDB found 0 allocation errors and 0 consistency errors in database ‘NORTHWND’.
The purpose of this exercise is to remind you that corrupted databases will occur, but the first step to solving the problem is to understand what is corrupted.