

What’s the difference between storing data in Excel and SQL Server? Schema.
A good schema can help maintain the integrity of your data, and improve the performance of your application. Entity Framework makes it so easy to create a new database, that it’s easy to forget what’s going on under the hood. I’ll present some techniques to make EF create databases with indexes, foreign keys, constraints, and inheritance using the Fluent API.
Entity Framework has three methods to create a database schema. The default method is “convention”. It uses built in rules based on the name of properties, and entity composition to create the schema. It’s the method most people use to get started, but you don’t have any control over them. Another way to configure the schema is to use annotations on the entity model to dictate how the schema is created. The last and most powerful, is to use the Fluent API. Configuration options you make using the Fluent API override annotations and conventions. Below is a common data model that I’ll use in my examples.
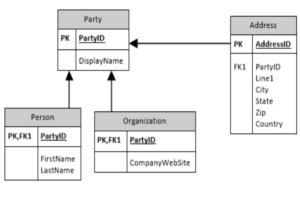
Identities and Constraints
EF will make the best choice it can when configuring the schema. For example, if the primary key is an integer, it will make the column an identity column by default. For every row that is added, the PK is set to the next highest integer in the column. If you wanted to be explicit about this option, you could do that by overriding the OnModelCreating method of the DbContext object.
public class CRMContext : DbContext
{
public DbSet<Address> Addresses {get; set;}
public DbSet<Party> Party {get; set;}
public DbSet<Person> People {get; set;}
public DbSet<Organization> Organizations {get; set;}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Party>()
.Property(p => p.PartyID
.UseSqlServerIdentityColumn();
}
}
Another convention that EF uses, is to create NVARCHAR(MAX) columns to store string data. It’s a safe guess because it’s flexible in the absence of knowledge about what kind of data will be stored. If you know that a column will be storing the names of people, you could specify the maximum length the column will store, and improve performance.
modelBuilder.Entity<Party>() .Property(p => p.DisplayName) .HasMaxLength(128);
Foreign Keys
In this example, a person or organization inherits from a party. Each has a collection of addresses that can be associated with them. This relationship is defined by creating a foreign key property on the database schema. Using the Fluent API, we begin by declaring the navigation properties of the relationship. This can be defined as “HasOne” or “HasMany”, depending on the carnality of the relationship. The inverse navigation can be chained to the definition by using “WithOne” or “WithMany”.
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Party>()
.HasMany(p => p.Addresses)
.WithOne(p => p.Party)
.HasForeignKey(p => p.PartyID)
.IsRequired()
.OnDelete(DeleteBehavior.Cascade);
}
After establishing the relationship and its carnality, we need to tell Entity Framework what the foreign key field is. This is done using HasForeignKey(). It doesn’t make sense to have an address that is not attached to a person or organization, so the foreign key should be required. This is done with the IsRequired() method. Because an address is tied to a party, when a party is deleted, we want the related addresses to be deleted as well. Cascading deletes in SQL Server can handle this problem for us, so we’ll apply that behavior with the OnDelete method.
Indexes
The next step is to create some indexes on the entities to improve performance. The HasIndex method is used to create an index based on one or more columns. By default the indexes do not require that each “row” be unique. That can be configured by using IsUnique.
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Party>()
.HasIndex(p => new { p.PartyID, p.DisplayName })
.IsUnique();
}
Inheritance
Inheritance in a database can take on two distince flavors. The table-per-hierarchy (TPH) pattern uses a single table to store all the data for all the types in the hierarchy. The table-per-type (TPT) pattern creates a table for each type in the hierarchy. Entity Framework currently only supports TPH. Because data for multiple types will be stored in the same table, an additional piece of information is needed to identify a row’s type. In EF, this column is called the discriminator. It can be added to the schema with the HasDiscriminator method. The values that can be placed in column are defined with the HasValue method.
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Party>()
.HasDiscriminator<string>("PartyType")
.HasValue<Person>("Person")
.HasValue<Organization>("Organization");
}

Because EF is using TPH, the Person DbSet and the Organization DbSet are merged into a Party table. This does limit our ability to use SQL constraints to enforce data integerity. For example, if we need to record the schools that a person has attended, there will be no foreign key constraint that can limit this to people. To prevent an organization from attending a school, we would need to create a insert and update trigger on the School table. TPT modeling would let us avoid having to use a trigger. At this point EF doesn’t support TPT modeling, but it is on Microsoft’s roadmap. Another thing to take note of is that the extensions needed to set the discriminator are in the Microsoft.EntityFrameworkCore.Relational package in NuGet.